
Summary
Gives Claude, Cursor, ChatGPT, and other MCP clients persistent memory across sessions through organized buckets you manage in a web dashboard. You get seven tools: semantic search across saved content, read/write for documents and conversations, and bucket management for organizing context by project or topic. Authentication works via OAuth for interactive use or PATs for headless agents and CI pipelines. The server talks to Plurality's API Gateway and vector service over HTTP, so memories sync everywhere you connect. Useful when you want agents to remember past conversations, reference saved research, or share context across different AI tools without re-explaining background every time.
Keep your Mac awake while Claude Code and 40+ AI agents run. Sleeps when they're idle.
One time payment $9 →Integrate web data into your AI product. One API to scrape website & brand data.
Get API Key Now →Agent, run crypto. Access onchain data & trade routes via 1inch.
Install now →On Capafy, your Skill runs online 24/7 as an agent product, and you get paid every time someone uses it.
Start earning →Tools
Public tool metadata for what this MCP can expose to an agent.
7 tools
get_user_memory_bucketsList all memory buckets (AI profiles) for the authenticated user. Each bucket is a themed collection of documents, notes, and files. Returns bucket IDs, names, and item counts. Use this first to discover available memory buckets before browsing or searching their contents. Ret...
List all memory buckets (AI profiles) for the authenticated user. Each bucket is a themed collection of documents, notes, and files. Returns bucket IDs, names, and item counts. Use this first to discover available memory buckets before browsing or searching their contents. Ret...
No parameter schema in public metadata yet.
list_items_in_memory_bucketList all stored items (documents, files, notes) inside a specific memory bucket. Returns item metadata including title, description, source type, file name, size, and chunk count — but not the actual content. Use this to browse what's stored in a bucket before reading or searc...1 params
List all stored items (documents, files, notes) inside a specific memory bucket. Returns item metadata including title, description, source type, file name, size, and chunk count — but not the actual content. Use this to browse what's stored in a bucket before reading or searc...
Parameters* required
profile_idstringsearch_memorySearch across the user's stored memory using semantic vector similarity. Finds relevant content even when the query doesn't exactly match stored text. Searches all memory buckets by default, or specify bucket IDs to narrow scope. Searches across both owned and shared buckets a...3 params
Search across the user's stored memory using semantic vector similarity. Finds relevant content even when the query doesn't exactly match stored text. Searches all memory buckets by default, or specify bucket IDs to narrow scope. Searches across both owned and shared buckets a...
Parameters* required
kintegerdefault: 5
querystringprofile_idsvalueread_contextRead the full content of a specific stored memory item (document, file, or note). Returns the actual text content with pagination support for large documents. Use start_chunk and limit to read specific portions — defaults to returning all content. Use this after finding an ite...3 params
Read the full content of a specific stored memory item (document, file, or note). Returns the actual text content with pagination support for large documents. Use start_chunk and limit to read specific portions — defaults to returning all content. Use this after finding an ite...
Parameters* required
limitintegerdefault: 0
context_idstringstart_chunkintegerdefault: 0
save_memorySave text content to a specific memory bucket. IMPORTANT — Before calling this tool: 1. Call get_user_memory_buckets to list available buckets 2. Ask the user which bucket to save to, or offer to create a new one 3. If the user wants a new bucket, call create_memory_bucket fir...4 params
Save text content to a specific memory bucket. IMPORTANT — Before calling this tool: 1. Call get_user_memory_buckets to list available buckets 2. Ask the user which bucket to save to, or offer to create a new one 3. If the user wants a new bucket, call create_memory_bucket fir...
Parameters* required
titlevaluecontentstringprofile_idstringsource_platformstringdefault: unknown
save_conversationSave a conversation (chat history) to a specific memory bucket. IMPORTANT — Before calling this tool: 1. Call get_user_memory_buckets to list available buckets 2. Ask the user which bucket to save to, or offer to create a new one 3. If the user wants a new bucket, call create_...4 params
Save a conversation (chat history) to a specific memory bucket. IMPORTANT — Before calling this tool: 1. Call get_user_memory_buckets to list available buckets 2. Ask the user which bucket to save to, or offer to create a new one 3. If the user wants a new bucket, call create_...
Parameters* required
titlevalueprofile_idstringchat_historyarraysource_platformstringdefault: unknown
create_memory_bucketCreate a new memory bucket (AI profile) for organizing saved content. Only use this when the user explicitly wants a new bucket. Always ask the user for confirmation before creating. Args: bucket_name: A descriptive name for the new bucket.1 params
Create a new memory bucket (AI profile) for organizing saved content. Only use this when the user explicitly wants a new bucket. Always ask the user for confirmation before creating. Args: bucket_name: A descriptive name for the new bucket.
Parameters* required
bucket_namestringPlurality MCP Server
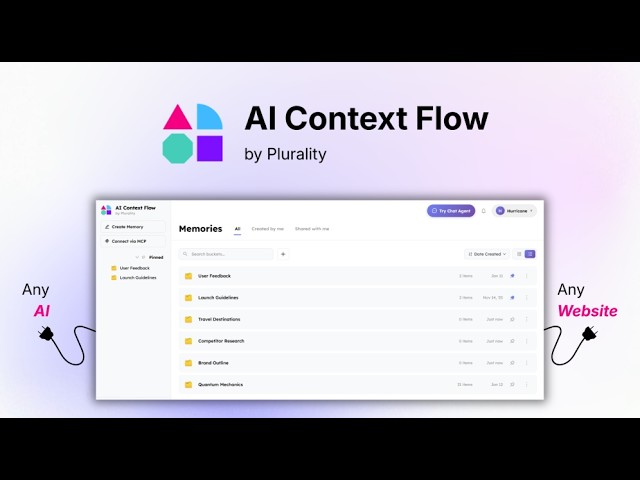
Universal memory for AI agents and tools. Save, organize and search context anywhere.

![]()
An Model Context Protocol server that gives any MCP-compatible AI client persistent memory — documents, notes, conversations, and files stored across organized memory buckets with semantic search. Supports OAuth and Personal Access Tokens (PAT) based authentication.
Why use this?
- Memory Studio — a personal knowledge base and second brain where you organize context into memory buckets, review saved content, and manage what your AI agents know.
- Save important chats — directly from within Claude, ChatGPT, Cursor, and other AI tools into the relevant memory bucket
- Shared persistent memory across all your agents — Claude Code, Lovable, Cursor, OpenClaw and more all access the same context
- Semantic search — find relevant memories using natural language, not just keywords
- Share buckets with other people — collaborate by giving others access to your context
- Works everywhere — any MCP-compatible client can connect
We also have a Chrome extension called AI Context Flow that lets you capture and use context on any website. It comes with a built-in chat agent (30+ models) that opens as a sidebar on any page — talk to your memories, answer questions from your stored context, and surface connections across everything you've saved. You can use the MCP Server alongside the extension to get full feature set of the product.
▶️ Watch the demo
📖 Full documentation · 🌐 Website · 🧩 Chrome Extension · 🧠 Memory Studio
Quick connect (production)
Production URL: https://app.plurality.network/mcp
The server supports OAuth 2.1 with PKCE (for interactive clients) and Personal Access Tokens (for headless agents and CI). Most clients handle the OAuth flow automatically.
Works with Claude Desktop, Claude Code, ChatGPT, Cursor, and any MCP-compatible client.
→ Step-by-step setup guides for all supported clients
Tools
| Tool | Description |
|---|---|
get_user_memory_buckets | List all memory buckets (organized folders) for the user |
list_items_in_memory_bucket | List stored items in a specific bucket (metadata only) |
search_memory | Semantic search across buckets with relevance scoring |
read_context | Read the full content of a stored item with pagination |
save_memory | Save text content to a specific memory bucket |
save_conversation | Save a conversation (chat history) to a memory bucket |
create_memory_bucket | Create a new memory bucket for organizing saved content |
Authentication
The MCP server accepts two auth methods:
| Method | When to use | Browser required? |
|---|---|---|
| OAuth 2.1 + PKCE | Interactive clients: Claude Desktop, Web, Code, ChatGPT | Yes (one-time) |
| Personal Access Token (PAT) | Headless agents, CI runners, custom integrations, n8n, LangChain | No |
Using a Personal Access Token
- Sign in to the dashboard, open Connect via MCP → Manage tokens
- Click Create token, give it a name and optional expiry, copy the
plur_pat_…value - Configure your client to send it as a Bearer token:
Authorization: Bearer plur_pat_...
PATs require a paid plan. They auto-revoke at expiry, can be rotated with a configurable grace period (default 7 days), and can be immediately revoked from the dashboard. They are stored hashed and never appear in logs.
OAuth details
The server uses Ory Hydra as the OAuth2/OIDC provider:
| Property | Value |
|---|---|
| Algorithm | RS256 |
| Issuer | https://app.plurality.network (prod) |
| Scope | openid offline_access mcp:tools |
| Access token TTL | 15 minutes |
| Refresh token TTL | 720 hours |
| Discovery | https://app.plurality.network/.well-known/oauth-authorization-server |
| Dynamic Client Registration | https://app.plurality.network/register |
OAuth2 flow (step by step)
- Client discovers auth server — fetches
/.well-known/oauth-protected-resourcefrom Traefik - Client registers — calls
/register(Dynamic Client Registration) to getclient_id/client_secret. The API Gateway proxies this to Hydra, injecting themcp:toolsscope - User authenticates — browser opens Hydra's login flow, which redirects to the frontend's login/consent pages
- Token issued — Hydra returns a JWT access token (RS256, 15min TTL) with the user's ID as the
subclaim andmcp:toolsscope - Authenticated requests — client includes
Authorization: Bearer <token>on all MCP requests - MCP server validates — JWT signature verified locally against Hydra's JWKS public keys (cached 1 hour),
mcp:toolsscope is checked - API Gateway access — MCP server forwards the Bearer token when calling API Gateway endpoints for data retrieval and storage
Architecture
MCP Client (Claude Code, Cursor, etc.)
│
│ OAuth2 + Streamable HTTP
▼
Traefik (:5050) ← single entrypoint for clients
├── /mcp → MCP Server (:5051)
├── /.well-known/* → API Gateway or Hydra
├── /oauth2/* → Hydra (:4444)
└── /register → API Gateway (DCR proxy)
│
│ Bearer token
▼
API Gateway (:5000)
│
▼
Vector Service (:8000)
Traefik is the single entrypoint. It routes OAuth traffic to Hydra and MCP protocol traffic to the MCP server. The MCP server validates JWTs locally via Hydra's JWKS keys, then forwards the Bearer token to the API Gateway for data access. The API Gateway handles authentication, DCR proxying, and routes vector/search operations to the Vector Service.
Local development setup
Prerequisites
- Python 3.11+
- uv (Python package manager)
- Docker and Docker Compose
- Running API Gateway (plurality-backend-api): Handles authentication, OAuth metadata, DCR proxying, and database access
- Running Vector Service (plurality-ai-service): Handles semantic search and vector database operations
1. Install dependencies
cd plurality-mcp-server
pip install uv
uv sync
2. Configure environment
cp .env.example .env
Default values work for local development — no changes needed if the API Gateway runs on :5000:
HYDRA_ISSUER=http://localhost:5050
MCP_RESOURCE_URL=http://localhost:5050
BACKEND_API_URL=http://localhost:5000
3. Start Docker services (Hydra + Traefik)
cd ory-hydra
docker compose up -d
This starts:
| Service | Port | Purpose |
|---|---|---|
| PostgreSQL | 5433 | Hydra's database |
| Hydra | 4444, 4445 | OAuth2/OIDC provider (public + admin) |
| Traefik | 5050 | Reverse proxy / routing |
Wait for services to be healthy: docker compose ps
4. Start the MCP server
uv run uvicorn main:mcp_server --host 0.0.0.0 --port 5051 --reload
Port 5051, not 5050. Traefik listens on 5050 and proxies
/mcpto the MCP server on 5051.
5. Verify
# Health check (direct)
curl http://localhost:5051/mcp/health
# OAuth metadata (via Traefik)
curl http://localhost:5050/.well-known/oauth-protected-resource
# Traefik dashboard (for debugging routes)
open http://localhost:8080
Local client configuration
Claude Code
claude mcp add --transport http plurality-memory http://localhost:5050/mcp
Then authenticate via /mcp inside Claude Code.
Claude Code — VS Code Extension
Authenticate first in the terminal using the steps above. Then add .mcp.json to your project root:
{
"mcpServers": {
"plurality-memory": {
"type": "http",
"url": "http://localhost:5050/mcp"
}
}
}
The VS Code extension may not trigger the OAuth browser flow automatically. Complete authentication via the terminal first.
Claude Desktop
Edit your config file:
- macOS:
~/Library/Application Support/Claude/claude_desktop_config.json - Windows:
%APPDATA%\Claude\claude_desktop_config.json
{
"mcpServers": {
"plurality-memory": {
"command": "npx",
"args": ["mcp-remote", "http://localhost:5050/mcp"]
}
}
}
Restart Claude Desktop fully, then authenticate when the browser opens.
MCP Inspector (debugging)
npx @modelcontextprotocol/inspector
Enter http://localhost:5050/mcp as the server URL. The inspector walks through the OAuth flow and lets you call tools interactively.
Note: ChatGPT is not supported for local development — it requires publicly reachable OAuth endpoints.
Project structure
plurality-mcp-server/
├── main.py # Entry point
├── pyproject.toml # Dependencies (managed by uv)
├── .env.example # Environment template
├── src/plurality_mcp_server/
│ ├── app.py # FastMCP app + middleware stack
│ ├── config.py # Env vars, shared HTTP client, context vars
│ ├── auth.py # JWT validation via Hydra JWKS + scope check
│ └── tools.py # MCP tool definitions (read + write)
└── ory-hydra/
├── docker-compose.yml # Hydra + Traefik + PostgreSQL
├── hydra.yml # Hydra OAuth2/OIDC config
├── traefik.yml # Traefik static config
└── dynamic.yml # Traefik routing rules
Troubleshooting
MCP client gets 401 Unauthorized
- Check that Hydra is running:
curl http://localhost:4444/.well-known/openid-configuration - Check that the JWT hasn't expired (15min TTL)
- Verify
HYDRA_ISSUERmatches the issuer in the token'sissclaim - Ensure the token has the
mcp:toolsscope
MCP client gets 502 Bad Gateway
- The MCP server isn't running on port 5051
- Check Traefik logs:
docker compose -f ory-hydra/docker-compose.yml logs traefik
Tools return "Error: Backend API returned status 401"
- The API Gateway needs to accept Hydra JWTs — ensure
jwks-rsais installed and the OAuth auth middleware is deployed
OAuth flow redirects to localhost:3000 but nothing is there
- Hydra is configured with
login: http://localhost:3000/login— this points to the Plurality frontend. Start the frontend or updatehydra.ymlURLs.
DCR returns unexpected scope or missing mcp:tools
- The API Gateway's DCR proxy injects
mcp:toolsinto the allowed scopes. Ensure the API Gateway is running and the/registerroute is reachable.
Links
Featured
Keep your Mac awake while Claude Code and 40+ AI agents run. Sleeps when they're idle.
One time payment $9 →Integrate web data into your AI product. One API to scrape website & brand data.
Get API Key Now →Agent, run crypto. Access onchain data & trade routes via 1inch.
Install now →On Capafy, your Skill runs online 24/7 as an agent product, and you get paid every time someone uses it.
Start earning →Categories
Registryactive
TransportHTTP
UpdatedMay 14, 2026