
Summary
Cortex builds a local knowledge graph of your codebase using tree-sitter parsing, then exposes it to Claude and other MCP clients through semantic search and relationship queries. It indexes files, symbols, architectural decision records, and the connections between them (calls, imports, deprecations), so your assistant retrieves the right context instead of dumping entire directories into the prompt. The setup is one command: `cortex init --bootstrap` scaffolds the index, installs git hooks to keep it fresh, and registers the MCP server with Claude Desktop or Codex. You get graph traversal queries, call graph lookups, and rule enforcement at retrieval time. Runs entirely local with WSL support for Windows users running Node in a Linux environment.
Keep your Mac awake while Claude Code and 40+ AI agents run. Sleeps when they're idle.
One time payment $9 →Integrate web data into your AI product. One API to scrape website & brand data.
Get API Key Now →Agent, run crypto. Access onchain data & trade routes via 1inch.
Install now →On Capafy, your Skill runs online 24/7 as an agent product, and you get paid every time someone uses it.
Start earning →Tools
Public tool metadata for what this MCP can expose to an agent.
30 tools
listAllEntitiesList and filter catalog entities with support for pagination, search, and various filters including groups, types, owners, and git repositories. If the client is trying to fetch data for teams, use 'type': 'team' in these APIs.16 params
List and filter catalog entities with support for pagination, search, and various filters including groups, types, owners, and git repositories. If the client is trying to fetch data for teams, use 'type': 'team' in these APIs.
Parameters* required
pageintegerPage number to return, 0-indexed. Default 0.default: 0
querystringFilter based on a [search query](https://docs.cortex.io/settings/search). This will search across entity properties. If provided, results will be sorted by relevance.default:
typesarrayFilter the response to specific types of entities. By default, this includes services, resources, and domains. Corresponds to the `x-cortex-type` field in the entity descriptor.
groupsarrayFilter based on groups, which correspond to the `x-cortex-groups` field in the Catalog Descriptor. Accepts a comma-delimited list of groups
ownersarrayFilter based on owner group names, which correspond to the `x-cortex-owners` field in the Catalog Descriptor. Accepts a comma-delimited list of owner group names
contextstring
Explain why you're invoking this tool now and how its output will be used.
Then state how this call supports your *overall objective* and fits into your broader plan across all tool calls (e.g., why this tool vs. others, and what step it unblocks).
Never share any personal details or sensitive information.
pageSizeintegerNumber of results to return per page, between 1 and 1000. Default 250.default: 250
includeLinksbooleanWhether to include links for each entity in the responsedefault: false
includeOwnersbooleanWhether to include ownership information for each entity in the responsedefault: false
hierarchyDepthstringDepth of the parent / children hierarchy nodes. Can be 'full' or a valid integerdefault: full
gitRepositoriesarraySupports only GitHub repositories in the `org/repo` format
includeArchivedbooleanWhether to include archived entities in the responsedefault: false
includeMetadatabooleanWhether to include custom data for each entity in the responsedefault: false
includeNestedFieldsarrayList of sub fields to include for different types
includeSlackChannelsbooleanWhether to include Slack channels for each entity in the response
includeHierarchyFieldsarrayList of sub fields to include for hierarchies. Only supports 'groups'
listEntityDescriptorsCortex Catalog API - Access and manage your service catalog, teams, domains, and resources5 params
Cortex Catalog API - Access and manage your service catalog, teams, domains, and resources
Parameters* required
pageintegerPage number to return, 0 indexed
yamlbooleanWhen true, returns the YAML representation of the descriptors
typesarrayFilter the response to specific types of entities. By default, this includes services, resources, and domains. Corresponds to the `x-cortex-type` field in the entity descriptor.
contextstring
Explain why you're invoking this tool now and how its output will be used.
Then state how this call supports your *overall objective* and fits into your broader plan across all tool calls (e.g., why this tool vs. others, and what step it unblocks).
Never share any personal details or sensitive information.
pageSizeintegerNumber of entities to return per page
listDependenciesForEntityList all dependencies for an entity including both incoming (who depends on this service) and outgoing (what this service depends on) relationships. Essential for understanding service interactions, planning changes, and assessing blast radius6 params
List all dependencies for an entity including both incoming (who depends on this service) and outgoing (what this service depends on) relationships. Essential for understanding service interactions, planning changes, and assessing blast radius
Parameters* required
pageintegerPage number to return, 0-indexed. Default 0.default: 0
contextstring
Explain why you're invoking this tool now and how its output will be used.
Then state how this call supports your *overall objective* and fits into your broader plan across all tool calls (e.g., why this tool vs. others, and what step it unblocks).
Never share any personal details or sensitive information.
pageSizeintegerNumber of results to return per page, between 1 and 1000. Default 250.default: 250
callerTagstringincludeIncomingbooleandefault: false
includeOutgoingbooleandefault: true
getDependencyGet specific dependency details between two entities including method, path, and metadata. Useful for understanding the nature of the relationship, API contracts, and communication patterns between services5 params
Get specific dependency details between two entities including method, path, and metadata. Useful for understanding the nature of the relationship, API contracts, and communication patterns between services
Parameters* required
pathstringmethodstringcontextstring
Explain why you're invoking this tool now and how its output will be used.
Then state how this call supports your *overall objective* and fits into your broader plan across all tool calls (e.g., why this tool vs. others, and what step it unblocks).
Never share any personal details or sensitive information.
calleeTagstringcallerTagstringgetEntityDetailsRetrieve comprehensive details about a specific entity including its metadata, ownership, hierarchies, and relationships. This is the primary method for getting complete information about services, teams, or domains.5 params
Retrieve comprehensive details about a specific entity including its metadata, ownership, hierarchies, and relationships. This is the primary method for getting complete information about services, teams, or domains.
Parameters* required
contextstring
Explain why you're invoking this tool now and how its output will be used.
Then state how this call supports your *overall objective* and fits into your broader plan across all tool calls (e.g., why this tool vs. others, and what step it unblocks).
Never share any personal details or sensitive information.
tagOrIdstringEntity identifier - can be a tag or CID
includeOwnersbooleanInclude ownership information, default is true
hierarchyDepthstringDepth of the parent / children hierarchy nodes. Can be 'full' or a valid integerdefault: full
includeHierarchyFieldsarrayList of sub fields to include for hierarchies. Only supports 'groups'
getCustomDataForEntityList all custom data key-value pairs associated with an entity. Retrieve metadata, configuration settings, and custom attributes stored for services, resources, or domains. Supports pagination for entities with large amounts of custom data4 params
List all custom data key-value pairs associated with an entity. Retrieve metadata, configuration settings, and custom attributes stored for services, resources, or domains. Supports pagination for entities with large amounts of custom data
Parameters* required
pageintegerPage number to return, 0-indexed. Default 0.default: 0
contextstring
Explain why you're invoking this tool now and how its output will be used.
Then state how this call supports your *overall objective* and fits into your broader plan across all tool calls (e.g., why this tool vs. others, and what step it unblocks).
Never share any personal details or sensitive information.
tagOrIdstringEntity identifier - can be a tag or CID
pageSizeintegerNumber of results to return per page, between 1 and 1000. Default 250.default: 250
getCustomDataForEntityByKeyRetrieve a specific custom data value by key for an entity. Efficiently access individual metadata attributes, configuration values, or custom properties without fetching all custom data3 params
Retrieve a specific custom data value by key for an entity. Efficiently access individual metadata attributes, configuration values, or custom properties without fetching all custom data
Parameters* required
keystringcontextstring
Explain why you're invoking this tool now and how its output will be used.
Then state how this call supports your *overall objective* and fits into your broader plan across all tool calls (e.g., why this tool vs. others, and what step it unblocks).
Never share any personal details or sensitive information.
tagOrIdstringEntity identifier - can be a tag or CID
listCustomEventsForEntityList custom events for an entity with optional filtering by type and time range. Supports pagination and filtering by event type, start time, and end time to retrieve historical event data8 params
List custom events for an entity with optional filtering by type and time range. Supports pagination and filtering by event type, start time, and end time to retrieve historical event data
Parameters* required
pageintegerPage number to return, 0-indexed. Default 0.default: 0
typestringcontextstring
Explain why you're invoking this tool now and how its output will be used.
Then state how this call supports your *overall objective* and fits into your broader plan across all tool calls (e.g., why this tool vs. others, and what step it unblocks).
Never share any personal details or sensitive information.
endTimestringIf provided, events with less than or equal to timestamp will be returned (a date-time without a time-zone in the ISO-8601 calendar system)
tagOrIdstringEntity identifier - can be a tag or CID
pageSizeintegerNumber of results to return per page, between 1 and 1000. Default 250.default: 250
startTimestringIf provided, events with greater than or equal to timestamp will be returned (a date-time without a time-zone in the ISO-8601 calendar system)
timestampstringUse 'startTime' instead
getCustomEventForEntityByUuidRetrieve a specific custom event by its UUID. Returns event details including title, description, timestamp, type, and any custom data associated with the event3 params
Retrieve a specific custom event by its UUID. Returns event details including title, description, timestamp, type, and any custom data associated with the event
Parameters* required
uuidstringcontextstring
Explain why you're invoking this tool now and how its output will be used.
Then state how this call supports your *overall objective* and fits into your broader plan across all tool calls (e.g., why this tool vs. others, and what step it unblocks).
Never share any personal details or sensitive information.
tagOrIdstringEntity identifier - can be a tag or CID
getDeploysForEntityList all deployments for a specific catalog entity. Returns deployment history including timestamps, environments, SHAs, and deployment types in paginated format4 params
List all deployments for a specific catalog entity. Returns deployment history including timestamps, environments, SHAs, and deployment types in paginated format
Parameters* required
pageintegerPage number to return, 0-indexed. Default 0.default: 0
contextstring
Explain why you're invoking this tool now and how its output will be used.
Then state how this call supports your *overall objective* and fits into your broader plan across all tool calls (e.g., why this tool vs. others, and what step it unblocks).
Never share any personal details or sensitive information.
tagOrIdstringEntity identifier - can be a tag or CID
pageSizeintegerNumber of results to return per page, between 1 and 1000. Default 250.default: 250
getCurrentOncallForEntityRetrieve the current on-call personnel for an entity in real-time. Shows who is actively responsible for incident response, including primary and secondary on-call, contact information, and rotation schedules2 params
Retrieve the current on-call personnel for an entity in real-time. Shows who is actively responsible for incident response, including primary and secondary on-call, contact information, and rotation schedules
Parameters* required
contextstring
Explain why you're invoking this tool now and how its output will be used.
Then state how this call supports your *overall objective* and fits into your broader plan across all tool calls (e.g., why this tool vs. others, and what step it unblocks).
Never share any personal details or sensitive information.
tagOrIdstringEntity identifier - can be a tag or CID
getEntityDescriptorCortex Catalog API - Access and manage your service catalog, teams, domains, and resources3 params
Cortex Catalog API - Access and manage your service catalog, teams, domains, and resources
Parameters* required
yamlbooleanWhen true, returns the YAML representation of the descriptor
contextstring
Explain why you're invoking this tool now and how its output will be used.
Then state how this call supports your *overall objective* and fits into your broader plan across all tool calls (e.g., why this tool vs. others, and what step it unblocks).
Never share any personal details or sensitive information.
tagOrIdstringEntity identifier - can be a tag or CID
listEntityDestinationsForRelationshipTypeList all destinations for a certain relationship type & entity. Use the listRelationshipTypes tool to find the relevant relationshipTypeTag.5 params
List all destinations for a certain relationship type & entity. Use the listRelationshipTypes tool to find the relevant relationshipTypeTag.
Parameters* required
depthstringMaximum depth to traverse in the relationship hierarchy. Defaults to 1 (i.e., direct relationships only).
contextstring
Explain why you're invoking this tool now and how its output will be used.
Then state how this call supports your *overall objective* and fits into your broader plan across all tool calls (e.g., why this tool vs. others, and what step it unblocks).
Never share any personal details or sensitive information.
tagOrIdstringEntity identifier - can be a tag or CID
includeArchivedbooleanIf true will include relationships that traverse archived entitiesdefault: false
relationshipTypeTagstringlistEntitySourcesForRelationshipTypeList all sources for a certain relationship type & entity. Use the listRelationshipTypes tool to find the relevant relationshipTypeTag.5 params
List all sources for a certain relationship type & entity. Use the listRelationshipTypes tool to find the relevant relationshipTypeTag.
Parameters* required
depthstringMaximum depth to traverse in the relationship hierarchy. Defaults to 1 (i.e., direct relationships only).
contextstring
Explain why you're invoking this tool now and how its output will be used.
Then state how this call supports your *overall objective* and fits into your broader plan across all tool calls (e.g., why this tool vs. others, and what step it unblocks).
Never share any personal details or sensitive information.
tagOrIdstringEntity identifier - can be a tag or CID
includeArchivedbooleanIf true will include relationships that traverse archived entitiesdefault: false
relationshipTypeTagstringgetCustomMetricDataRetrieve custom metric data points for an entity. Returns paginated time-series data for a specific custom metric, with optional filtering by date range to analyze trends and patterns7 params
Retrieve custom metric data points for an entity. Returns paginated time-series data for a specific custom metric, with optional filtering by date range to analyze trends and patterns
Parameters* required
pageintegerPage number to return, 0-indexed. Default 0.default: 0
contextstring
Explain why you're invoking this tool now and how its output will be used.
Then state how this call supports your *overall objective* and fits into your broader plan across all tool calls (e.g., why this tool vs. others, and what step it unblocks).
Never share any personal details or sensitive information.
endDatestringEnd date for the filter (inclusive)
tagOrIdstringEntity identifier - can be a tag or CID
pageSizeintegerNumber of results to return per page, between 1 and 1000. Default 250.default: 250
startDatestringStart date for the filter (inclusive). Default: 6 months
customMetricKeystringKey for the custom metric filter
queryPointInTimeMetricsExecute point-in-time queries for one or more engineering metrics. Returns current metric values for specified time periods, with support for batch queries and optional period-over-period comparisons. Time range (startTime/endTime) cannot exceed 6 months (180 days). PREREQUISI...14 params
Execute point-in-time queries for one or more engineering metrics. Returns current metric values for specified time periods, with support for batch queries and optional period-over-period comparisons. Time range (startTime/endTime) cannot exceed 6 months (180 days). PREREQUISI...
Parameters* required
limitintegerMaximum number of results to return
contextstring
Explain why you're invoking this tool now and how its output will be used.
Then state how this call supports your *overall objective* and fits into your broader plan across all tool calls (e.g., why this tool vs. others, and what step it unblocks).
Never share any personal details or sensitive information.
endTimestringEnd time for the query period
filtersarrayFilters to apply to the data
groupByarrayFields to group results by
metricsarrayList of metrics to query with their aggregation functions
orderByarraySort order for results
nextPagestringPagination token for next page of results
startTimestringStart time for the query period
comparisonvaluenestedGroupByarrayFields to group nested results by
nestedMetricsarrayOptional nested metrics for advanced queries
timeAttributestringTime attribute to use for queries
nestedTimeAttributestringTime attribute for nested queries
listMetricDefinitionsList all available engineering metric definitions. USAGE - Call this endpoint BEFORE querying metrics (queryPointInTimeMetrics): 1. Once at start: Call with view='basic' to discover all available metrics - cache this response 2. Once per metric: Call with view='full' and key=M...3 params
List all available engineering metric definitions. USAGE - Call this endpoint BEFORE querying metrics (queryPointInTimeMetrics): 1. Once at start: Call with view='basic' to discover all available metrics - cache this response 2. Once per metric: Call with view='full' and key=M...
Parameters* required
keyarrayviewstringdefault: basic
contextstring
Explain why you're invoking this tool now and how its output will be used.
Then state how this call supports your *overall objective* and fits into your broader plan across all tool calls (e.g., why this tool vs. others, and what step it unblocks).
Never share any personal details or sensitive information.
listInitiativesList all initiatives in the organization with optional filters for draft and expired initiatives. View active improvement programs, strategic projects, and their current status to understand organizational priorities and track progress5 params
List all initiatives in the organization with optional filters for draft and expired initiatives. View active improvement programs, strategic projects, and their current status to understand organizational priorities and track progress
Parameters* required
pageintegerPage number to return, 0-indexed. Default 0.default: 0
contextstring
Explain why you're invoking this tool now and how its output will be used.
Then state how this call supports your *overall objective* and fits into your broader plan across all tool calls (e.g., why this tool vs. others, and what step it unblocks).
Never share any personal details or sensitive information.
pageSizeintegerNumber of results to return per page, between 1 and 1000. Default 250.default: 250
includeDraftsbooleanWhether or not to include draft Initiatives in the responsedefault: false
includeExpiredbooleanWhether or not to include expired Initiatives in the responsedefault: false
getInitiativeRetrieve detailed information about a specific initiative including its goals, timeline, affected entities, scorecard targets, and current progress. Essential for understanding initiative scope and tracking achievement of objectives2 params
Retrieve detailed information about a specific initiative including its goals, timeline, affected entities, scorecard targets, and current progress. Essential for understanding initiative scope and tracking achievement of objectives
Parameters* required
cidstringcontextstring
Explain why you're invoking this tool now and how its output will be used.
Then state how this call supports your *overall objective* and fits into your broader plan across all tool calls (e.g., why this tool vs. others, and what step it unblocks).
Never share any personal details or sensitive information.
getMyWorkspaceTOOL for retrieving current user's owned resources and work items across the Cortex workspace. FLEXIBLE REQUEST STRUCTURE: The request accepts an object with optional fields for each resource type: - myEntitiesRequest: Fetch entities (services, resources, domains) owned by the...7 params
TOOL for retrieving current user's owned resources and work items across the Cortex workspace. FLEXIBLE REQUEST STRUCTURE: The request accepts an object with optional fields for each resource type: - myEntitiesRequest: Fetch entities (services, resources, domains) owned by the...
Parameters* required
contextstring
Explain why you're invoking this tool now and how its output will be used.
Then state how this call supports your *overall objective* and fits into your broader plan across all tool calls (e.g., why this tool vs. others, and what step it unblocks).
Never share any personal details or sensitive information.
myTeamsRequestobjectRequest for teams the user belongs to
myOpenPRsRequestobjectRequest for user's open pull requests across all Git repositories
myEntitiesRequestobjectRequest for all entities (services, resources, domains) owned by the user
myWorkItemsRequestobjectRequest for work items (Jira, Linear, Azure DevOps issues) assigned to the user
myScorecardsRequestobjectRequest for scorecards associated with the user's entities
myRequestedReviewsRequestobjectRequest for pull requests where the user is requested as a reviewer
listRelationshipTypesList all available relationship types with pagination. View relationship type configurations to understand what kinds of relationships can be created between entities like services, resources, domains, and teams3 params
List all available relationship types with pagination. View relationship type configurations to understand what kinds of relationships can be created between entities like services, resources, domains, and teams
Parameters* required
pageintegerPage number to return, 0-indexed. Default 0.default: 0
contextstring
Explain why you're invoking this tool now and how its output will be used.
Then state how this call supports your *overall objective* and fits into your broader plan across all tool calls (e.g., why this tool vs. others, and what step it unblocks).
Never share any personal details or sensitive information.
pageSizeintegerNumber of results to return per page, between 1 and 1000. Default 250.default: 250
getRelationshipTypeDetailsGet complete details of a specific relationship type including its configuration, rules, source/destination filters, and inheritance settings. Essential for understanding how entities can be connected and what validation rules apply2 params
Get complete details of a specific relationship type including its configuration, rules, source/destination filters, and inheritance settings. Essential for understanding how entities can be connected and what validation rules apply
Parameters* required
contextstring
Explain why you're invoking this tool now and how its output will be used.
Then state how this call supports your *overall objective* and fits into your broader plan across all tool calls (e.g., why this tool vs. others, and what step it unblocks).
Never share any personal details or sensitive information.
relationshipTypeTagstringlistEntityRelationshipsList all entity relationships/full graph for a specific relationship type across the entire organization. Returns paginated results showing all source-destination pairs, useful for understanding the complete relationship graph and finding all connections of a particular type4 params
List all entity relationships/full graph for a specific relationship type across the entire organization. Returns paginated results showing all source-destination pairs, useful for understanding the complete relationship graph and finding all connections of a particular type
Parameters* required
pageintegerPage number to return, 0-indexed. Default 0.default: 0
contextstring
Explain why you're invoking this tool now and how its output will be used.
Then state how this call supports your *overall objective* and fits into your broader plan across all tool calls (e.g., why this tool vs. others, and what step it unblocks).
Never share any personal details or sensitive information.
pageSizeintegerNumber of results to return per page, between 1 and 1000. Default 250.default: 250
relationshipTypeTagstringlistScorecardsList all scorecards in the organization with optional filtering. View scorecard configurations to understand quality standards, compliance requirements, and maturity models. Supports filtering by groups, entities, and teams to find relevant scorecards7 params
List all scorecards in the organization with optional filtering. View scorecard configurations to understand quality standards, compliance requirements, and maturity models. Supports filtering by groups, entities, and teams to find relevant scorecards
Parameters* required
pageintegerPage number to return, 0-indexed. Default 0.default: 0
teamsarrayFilter based on team (either tags or CIDs). Accepts a comma-delimited list of team tag or CIDs, please use only one type of identifier
groupsarrayFilter based on groups, which correspond to the `x-cortex-groups` field in the Catalog Descriptor. Accepts a comma-delimited list of groups
contextstring
Explain why you're invoking this tool now and how its output will be used.
Then state how this call supports your *overall objective* and fits into your broader plan across all tool calls (e.g., why this tool vs. others, and what step it unblocks).
Never share any personal details or sensitive information.
entitiesarrayFilter based on entity (either tags or CIDs). Accepts a comma-delimited list of entity tag or CIDs, please use only one type of identifier
pageSizeintegerNumber of results to return per page, between 1 and 1000. Default 250.default: 250
showDraftsbooleangetScorecardGet complete details of a scorecard including its configuration, rules, levels, weights, exemption settings, and evaluation criteria. Essential for understanding how services are evaluated and what standards they must meet2 params
Get complete details of a scorecard including its configuration, rules, levels, weights, exemption settings, and evaluation criteria. Essential for understanding how services are evaluated and what standards they must meet
Parameters* required
tagstringUnique tag for the Scorecard
contextstring
Explain why you're invoking this tool now and how its output will be used.
Then state how this call supports your *overall objective* and fits into your broader plan across all tool calls (e.g., why this tool vs. others, and what step it unblocks).
Never share any personal details or sensitive information.
getScorecardNextStepsForEntityGet actionable next steps for an entity to improve its scorecard performance. Shows which rules need to be satisfied to reach the next maturity level, helping teams prioritize improvements and track progress toward compliance goals3 params
Get actionable next steps for an entity to improve its scorecard performance. Shows which rules need to be satisfied to reach the next maturity level, helping teams prioritize improvements and track progress toward compliance goals
Parameters* required
tagstringUnique tag for the Scorecard
contextstring
Explain why you're invoking this tool now and how its output will be used.
Then state how this call supports your *overall objective* and fits into your broader plan across all tool calls (e.g., why this tool vs. others, and what step it unblocks).
Never share any personal details or sensitive information.
entityTagstringThe entity tag (`x-cortex-tag`) that identifies the entity.
listScorecardScoresRetrieve scores for all entities evaluated by a specific scorecard. Returns paginated results showing how each service, resource, or domain performs against the scorecard's rules, including individual rule scores and overall scorecard scores5 params
Retrieve scores for all entities evaluated by a specific scorecard. Returns paginated results showing how each service, resource, or domain performs against the scorecard's rules, including individual rule scores and overall scorecard scores
Parameters* required
tagstringUnique tag for the Scorecard
pageintegerPage number to return, 0-indexed. Default 0.default: 0
contextstring
Explain why you're invoking this tool now and how its output will be used.
Then state how this call supports your *overall objective* and fits into your broader plan across all tool calls (e.g., why this tool vs. others, and what step it unblocks).
Never share any personal details or sensitive information.
pageSizeintegerNumber of results to return per page, between 1 and 1000. Default 250.default: 250
entityTagstringEntity tag (x-cortex-tag)
getTeamDetailsRetrieve detailed information about a specific team by its tag or ID. Returns complete team data including members, slack channels, metadata, and whether it's backed by an identity provider group2 params
Retrieve detailed information about a specific team by its tag or ID. Returns complete team data including members, slack channels, metadata, and whether it's backed by an identity provider group
Parameters* required
contextstring
Explain why you're invoking this tool now and how its output will be used.
Then state how this call supports your *overall objective* and fits into your broader plan across all tool calls (e.g., why this tool vs. others, and what step it unblocks).
Never share any personal details or sensitive information.
tagOrIdstringEntity identifier - can be a tag or CID
query_docsQuery the Cortex knowledge base for answers. Args: query: The question to ask Cortex docs Returns: Response from Cortex including answer and metadata2 params
Query the Cortex knowledge base for answers. Args: query: The question to ask Cortex docs Returns: Response from Cortex including answer and metadata
Parameters* required
querystringcontextstring
Explain why you're invoking this tool now and how its output will be used.
Then state how this call supports your *overall objective* and fits into your broader plan across all tool calls (e.g., why this tool vs. others, and what step it unblocks).
Never share any personal details or sensitive information.
get_more_toolsCheck for additional tools whenever your task might benefit from specialized capabilities - even if existing tools could work as a fallback.1 params
Check for additional tools whenever your task might benefit from specialized capabilities - even if existing tools could work as a fallback.
Parameters* required
contextvaluedefault:
![]()
Cortex
The context layer for AI-assisted software engineering.



What Cortex is
Cortex is a local, repository-scoped context engine for coding assistants. It parses your source code with tree-sitter, indexes it into a structured knowledge graph of entities (files, symbols, rules, ADRs) and their relationships (calls, defines, constrains, implements, supersedes), and exposes that context through CLI commands. MCP remains available as a compatibility and integration bridge for clients that support it.
Where a general-purpose AI assistant sees your codebase as a pile of text files, Cortex gives it a precise map: what exists, how it is connected, which rules govern it, and which parts are source-of-truth versus deprecated.
Cortex runs entirely on the developer's machine. Source code never leaves the host.
When to use Cortex
Cortex is designed for engineering teams that rely on AI assistants for non-trivial work on real codebases. Use it when:
- Your codebase is large or fragmented enough that assistants waste context window on irrelevant files.
- You need assistants to respect architectural rules, deprecations, and source-of-truth decisions already made by the team.
- You work across multiple languages and want consistent, structured retrieval across all of them.
- Security or compliance requires that source code stay on-premise and that all AI interactions remain auditable.
- You want retrieval to surface existing functionality before an assistant proposes new code — reducing duplication and drift.
Cortex is not a replacement for your editor, your version control, or your coding assistant. It is the grounding layer that makes those assistants act with knowledge of your specific repository.
Benefits
- Higher-quality suggestions. Assistants see the right files and rules instead of guessing from filenames.
- Lower token cost. Targeted retrieval replaces broad file reads. Typical sessions use a fraction of the context a raw assistant would consume.
- Architectural governance. Rules and ADRs are surfaced with every answer, so assistants follow the team's established patterns rather than generic best practices.
- Multi-language coverage. A single engine indexes multiple languages through tree-sitter grammars, giving polyglot teams consistent tooling.
- Privacy by design. Your code and its derived index stay on your machine. No upload, no cloud dependency for the core product.
- Low friction. One command (
cortex init --bootstrap) scaffolds everything needed for local indexing, git hooks, CLI retrieval, and optional MCP compatibility.
How it works
Cortex operates as a five-stage pipeline between your repository and your AI assistant.
- Ingestion. Source files are parsed with tree-sitter, producing structured entities (files, functions, classes, rules, ADRs) and relations (
CALLS,DEFINES,CONSTRAINS,IMPLEMENTS,IMPORTS,SUPERSEDES). - Storage. Entities and relations are persisted to a local graph database (RyuGraph). An optional vector index provides semantic search across entity content.
- Retrieval. CLI commands combine semantic search with graph traversal to assemble the smallest context package that answers the task.
- Policy. Architectural rules and source-of-truth markers filter conflicting or deprecated content before it reaches the assistant.
- Assembly. Results are delivered as compact, ranked context packages over
cortex ... --json, with MCP exposing equivalent tool responses when enabled.
Git hooks keep the index fresh on every checkout, pull, commit, and rewrite. A live TUI dashboard (cortex dashboard) shows what Cortex adds to the repository in real time.
Why it works
Modern coding assistants are bottlenecked by context, not by model capability. Feeding a model more files rarely helps; feeding it the right files almost always does.
Cortex is built on one principle: prefer retrieval quality over analysis completeness. A smaller, sharper context package outperforms a broad dump of files. Every component — from tree-sitter parsing to graph traversal to rule filtering — exists to raise the signal-to-noise ratio of what the assistant sees.
The result is an assistant that behaves as if it already knows your codebase, because — through Cortex — it does.
Quick demo
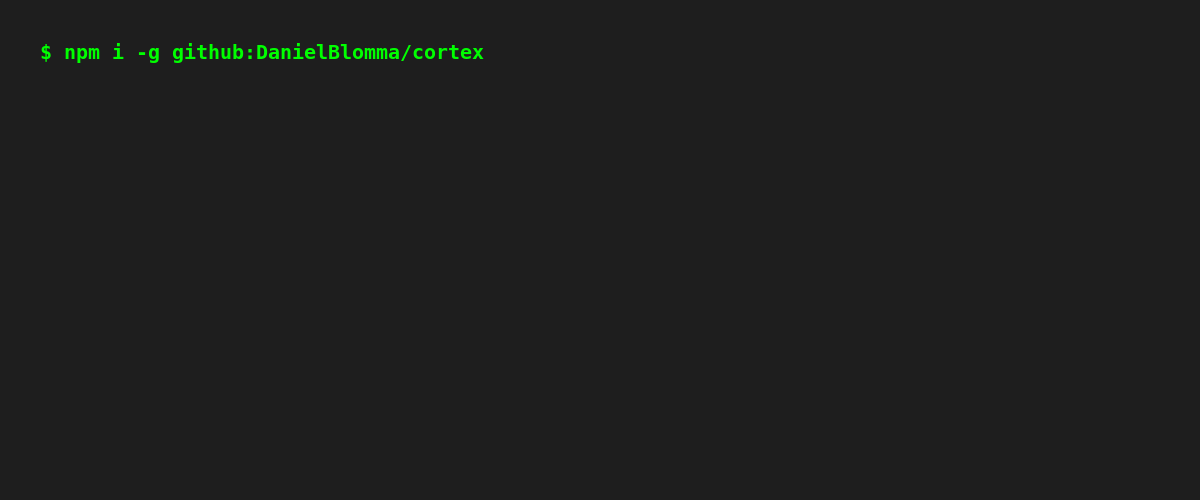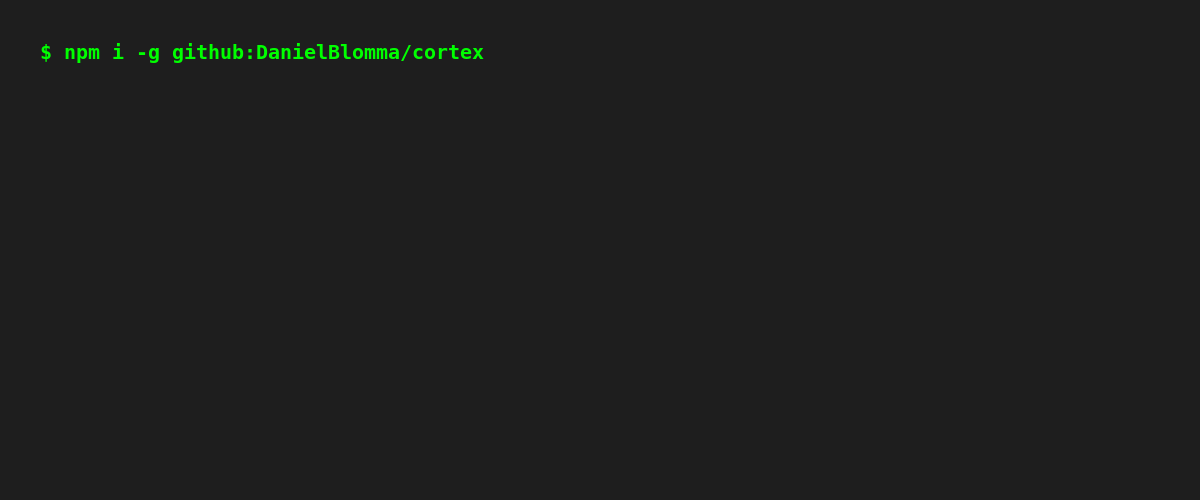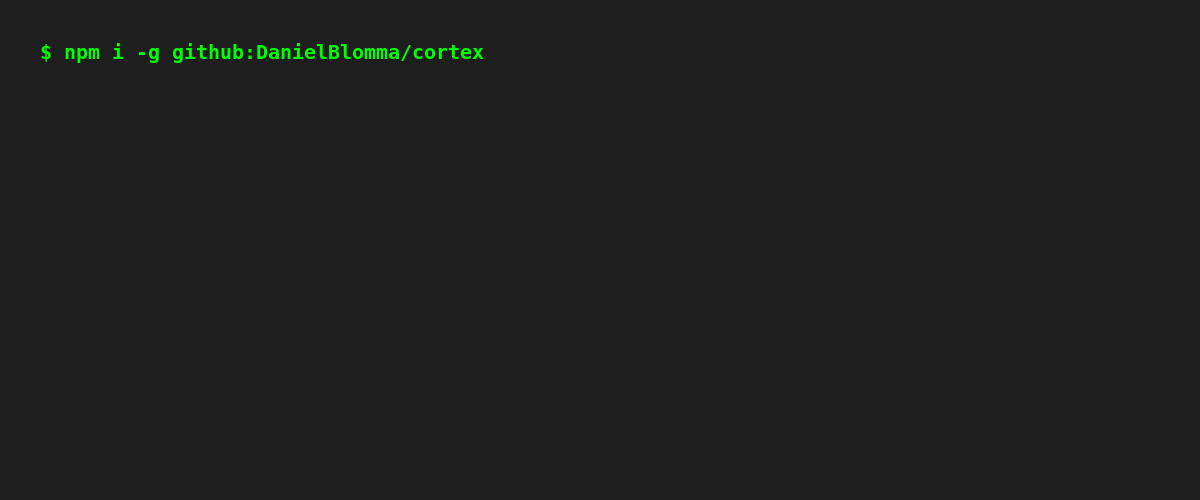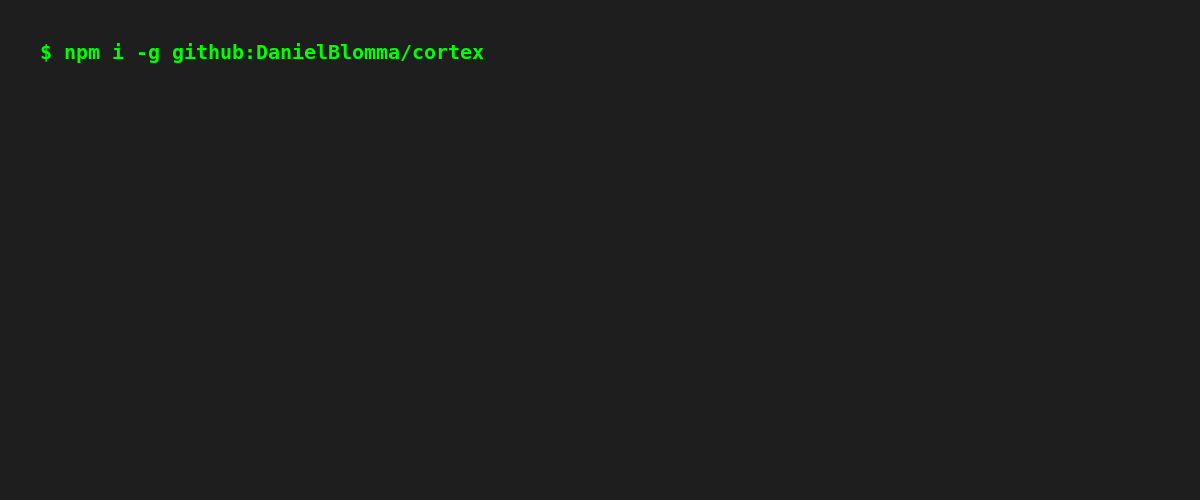
Core capabilities
- Semantic search across code, rules, and ADRs.
- Graph relationships between entities and architectural constraints.
- Call-graph traversal, caller lookup, and impact analysis.
- Architectural rules and ADR enforcement at retrieval time.
- Incremental index updates driven by git hooks.
- Live TUI dashboard showing what Cortex adds to your repository.
- CLI-first retrieval commands for local agents and scripts.
- Optional MCP integrations with Claude Code, Claude Desktop, and Codex.
Requirements
- Node.js 20+
- Git repository
- Optional for MCP registration:
claudeand/orcodexCLI inPATH
Install
npm i -g @danielblomma/cortex-mcp
Upgrading
To upgrade an already-scaffolded project to a new Cortex version:
npm i -g @danielblomma/cortex-mcp
cortex init --force # re-scaffolds .context runtime + .context/scripts
cortex bootstrap
cortex update
cortex init --force preserves per-project files: .context/config.yaml,
.context/rules.yaml, and your notes/decisions.
Version-specific notes (see CHANGELOG.md for details):
- 2.1.0: the default embedding model changed, so the first
cortex updateafter upgrading triggers a full re-embed automatically (~2 min per 1000 entities plus a one-time model download). TheCORTEX_EMBED_MAX_CHARSenv var is removed and silently ignored. Existing projects keep their old ranking weights inconfig.yaml; the recommended block is nowsemantic: 0.55, graph: 0.10, trust: 0.20, recency: 0.15. If you use MCP, restart the MCP server after re-embedding. The first search after a re-embed can hit a stale embeddings cache — re-run the query.
Quick Start
From the repository you want to index:
cortex init --bootstrap
This will:
- scaffold
.context/,.context/scripts/, the local context runtime (.context/mcpcompatibility path),.githooks/, and docs files - activate git hooks for checkout, pull/merge, commit, and rewrite events
- build and prepare the local context runtime
- leave MCP client registration opt-in via
cortex connectorcortex init --connect - start background sync unless disabled
Disable watcher setup:
cortex init --bootstrap --no-watch
Check context status:
cortex status
Query From The CLI
Use the CLI as the default local agent interface:
cortex search "authentication flow" --json
cortex related file:src/auth.ts --json
cortex impact "payment service" --json
cortex rules --json
cortex explain "where retries are configured" --json
These commands read the same local graph, embeddings, and rules used by the MCP server, but they do not require an MCP client registration.
Optional MCP Connection
MCP remains supported for clients that need it. Register MCP clients explicitly:
cortex connect
Then verify the client registration:
Claude:
claude mcp list
Codex:
codex mcp list
Claude Plugin Marketplace
Install via Claude Code plugin marketplace:
/plugin marketplace add DanielBlomma/cortex
/plugin install cortex@cortex-marketplace
/plugin enable cortex
Then initialize Cortex in your target repository. If you want the plugin to call the local MCP server, also run cortex connect from that repository:
cortex init --bootstrap
cortex connect
Manual MCP Configuration
If client registration is unavailable, configure MCP manually.
Claude Desktop (~/Library/Application Support/Claude/claude_desktop_config.json):
{
"mcpServers": {
"cortex": {
"command": "cortex",
"args": ["mcp"],
"env": {
"CORTEX_PROJECT_ROOT": "/absolute/path/to/your-project"
}
}
}
}
Codex (~/.config/codex/mcp-config.json):
{
"mcpServers": {
"cortex-myproject": {
"command": "cortex",
"args": ["mcp"],
"cwd": "/absolute/path/to/your-project"
}
}
}
WSL Mode (Windows)
If you run Node.js inside WSL but use Claude Desktop or another MCP client on Windows:
- Install Cortex inside WSL:
# In a WSL terminal
npm i -g @danielblomma/cortex-mcp
cd /mnt/c/Users/yourname/your-project
cortex init --bootstrap
- Configure Claude Desktop (
%APPDATA%\Claude\claude_desktop_config.json):
{
"mcpServers": {
"cortex": {
"command": "wsl.exe",
"args": ["--distribution", "Ubuntu", "--exec", "cortex", "mcp"],
"env": {
"CORTEX_PROJECT_ROOT": "C:\\Users\\yourname\\your-project",
"CORTEX_AUTO_BOOTSTRAP_ON_MCP": "1"
}
}
}
}
Cortex automatically converts Windows paths (e.g. C:\Users\...) to WSL paths (/mnt/c/Users/...).
For projects on the WSL filesystem (e.g. ~/projects/myapp), use the WSL path directly:
{
"mcpServers": {
"cortex": {
"command": "wsl.exe",
"args": ["--distribution", "Ubuntu", "--exec", "cortex", "mcp"],
"env": {
"CORTEX_PROJECT_ROOT": "/home/yourname/projects/myapp",
"CORTEX_AUTO_BOOTSTRAP_ON_MCP": "1"
}
}
}
}
Notes:
- File watching on
/mnt/paths (Windows filesystem) automatically uses poll mode sinceinotifyis unreliable across filesystem boundaries. - For best performance, keep projects on the WSL filesystem (
~/...) rather than/mnt/c/....
MCP Tool Compatibility
context.search
Ranked context search across indexed entities.
Input:
query(string, required)top_k(int, 1-20, default5)include_deprecated(bool, defaultfalse)include_content(bool, defaultfalse)
context.get_related
Fetch entity relationships from the graph.
Input:
entity_id(string, required)depth(int, 1-3, default1)include_edges(bool, defaulttrue)
context.impact
Traverse likely impact paths across config, code and SQL starting from an entity id or query.
Input:
entity_id(string, optional) — eitherentity_idorqueryis requiredquery(string, optional)depth(int, 1-4, default2)top_k(int, 1-20, default8)include_edges(bool, defaulttrue)profile("all"|"config_only"|"config_to_sql"|"code_only"|"sql_only", default"all")sort_by("impact_score"|"shortest_path"|"semantic_score"|"graph_score"|"trust_score", default"impact_score")
context.get_rules
List indexed rules and optionally include inactive rules.
Input:
scope(string, optional)include_inactive(bool, defaultfalse)
context.reload
Reload the RyuGraph connection after updates/maintenance.
Input:
force(bool, defaulttrue)
Example Prompts
- "Find files that handle authentication."
- "Show related files for this ADR."
- "What active architectural rules apply to this API?"
Dashboard
A live TUI that shows what Cortex adds to your repository at a glance.
cortex dashboard
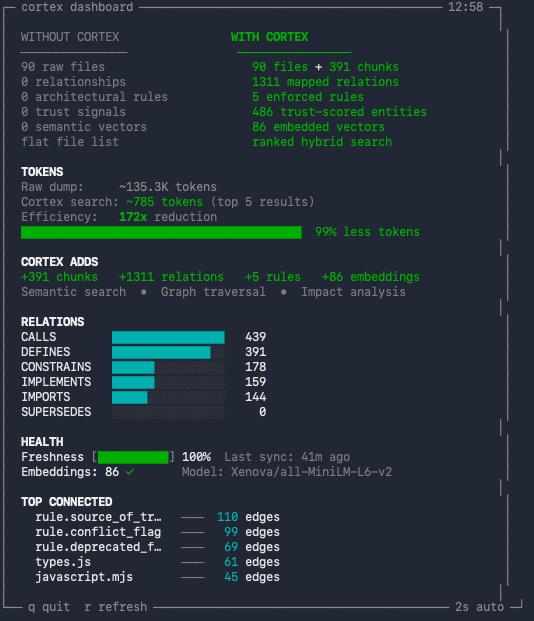
The dashboard displays:
- WITHOUT vs WITH CORTEX — side-by-side comparison of raw files versus indexed entities (files, chunks, relations, rules, embeddings, trust signals).
- TOKENS — per-task token estimate comparing typical LLM file reads without Cortex (~12 files) versus Cortex searches (~3 queries). Shows the reduction ratio and percentage.
- CORTEX ADDS — summary of what Cortex layers on top: chunks, relations, rules, embeddings, and which capabilities are unlocked (semantic search, graph traversal, impact analysis).
- RELATIONS — bar chart of relation types in the graph (CALLS, DEFINES, CONSTRAINS, IMPLEMENTS, IMPORTS, SUPERSEDES) and their counts.
- HEALTH — freshness percentage (how up-to-date the index is relative to uncommitted changes), last sync timestamp, and embedding status with model name.
- TOP CONNECTED — the five most connected entities in the graph by edge count, showing which files or rules are central to the codebase.
Options:
--interval <sec>— auto-refresh interval (default: 2 seconds).- Press
rto force refresh,qto quit. - Non-TTY output (piped) produces a single snapshot with ANSI stripped.
Common Commands
cortex init [path] [--force] [--bootstrap] [--connect] [--no-connect] [--watch] [--no-watch]
cortex connect [path] [--skip-build]
cortex mcp
cortex bootstrap
cortex update
cortex search <query> [--json]
cortex related <entity-id> [--json]
cortex impact <query|entity-id> [--json]
cortex rules [--json]
cortex explain <query|entity-id> [--json]
cortex status
cortex dashboard [--interval <sec>]
cortex watch [start|stop|status|run|once] [--interval <sec>] [--debounce <sec>] [--mode <auto|event|poll>]
cortex help
Automated Release
This repository includes two GitHub Actions workflows:
-
Release Bump(.github/workflows/release-bump.yml)- Manual
workflow_dispatchfrommain - Bumps semver (
patch/minor/major) - Syncs release metadata files (
package.json,server.json, plugin manifests) - Runs tests
- Commits and tags
vX.Y.Z
- Manual
-
Release Publish(.github/workflows/release-publish.yml)- Triggers on tag push
v*.*.* - Verifies tag/version sync
- Runs root tests + context runtime/MCP build/tests
- Publishes
@danielblomma/cortex-mcpto npm via npm trusted publishing (GitHub OIDC)
- Triggers on tag push
Required npm configuration:
- Configure a trusted publisher for
@danielblomma/cortex-mcpon npmjs.com - Use GitHub Actions publisher
DanielBlomma/cortex - Workflow filename must match
release-publish.yml
Embedding performance
Embedding generation tunes itself to the machine: the number of parallel
workers, memory limits for long files, and skip-work caching are all derived
from the available CPU cores and RAM at run time (container memory limits
included). No configuration is needed — on a laptop or a CI runner, cortex
picks safe, fast settings by itself. The one exception worth knowing:
when several cortex instances share one machine, set CORTEX_EMBED_THREADS
to give each its fair share of cores.
Limitations
- Requires repo initialization (
cortex init --bootstrap). - Each repository has its own local Cortex context instance.
- No cloud sync by design (privacy-first local storage).
Security and Privacy
- Cortex stores context data locally under
.context/. - No source code upload is required for core functionality.
Troubleshooting
- context runtime missing or
mcp/dist/server.jsmissing: Runcortex bootstrap(or re-runcortex init --bootstrap). claudeorcodexnot found duringcortex connect: MCP registration is skipped for that client; use manual config above if needed.- MCP tools return stale context:
Run
cortex update, then rerun the CLI query. If you use MCP, reconnect the client or callcontext.reload.
Website and Benchmarks
frontend/hosts the cortex website (GitHub Pages, deployed on push tomain): product overview plus bootstrap evaluation metrics.benchmark/bootstrapbench/runscortex bootstrapagainst 69 pinned real-world repositories in isolated containers and extracts chunk, embedding and graph statistics. See benchmark/bootstrapbench/README.md.
Support
- Issues: https://github.com/DanielBlomma/cortex/issues
- MCP registry submission draft: mcp-registry-submission.json
License
MIT
Featured
Keep your Mac awake while Claude Code and 40+ AI agents run. Sleeps when they're idle.
One time payment $9 →Integrate web data into your AI product. One API to scrape website & brand data.
Get API Key Now →Agent, run crypto. Access onchain data & trade routes via 1inch.
Install now →On Capafy, your Skill runs online 24/7 as an agent product, and you get paid every time someone uses it.
Start earning →Categories
Registryactive
Package@danielblomma/cortex-mcp
TransportSTDIO
UpdatedMar 3, 2026